1. Giới thiệu về mô hình cấu trúc trong SmartPLS 4 SmartPLS 4......
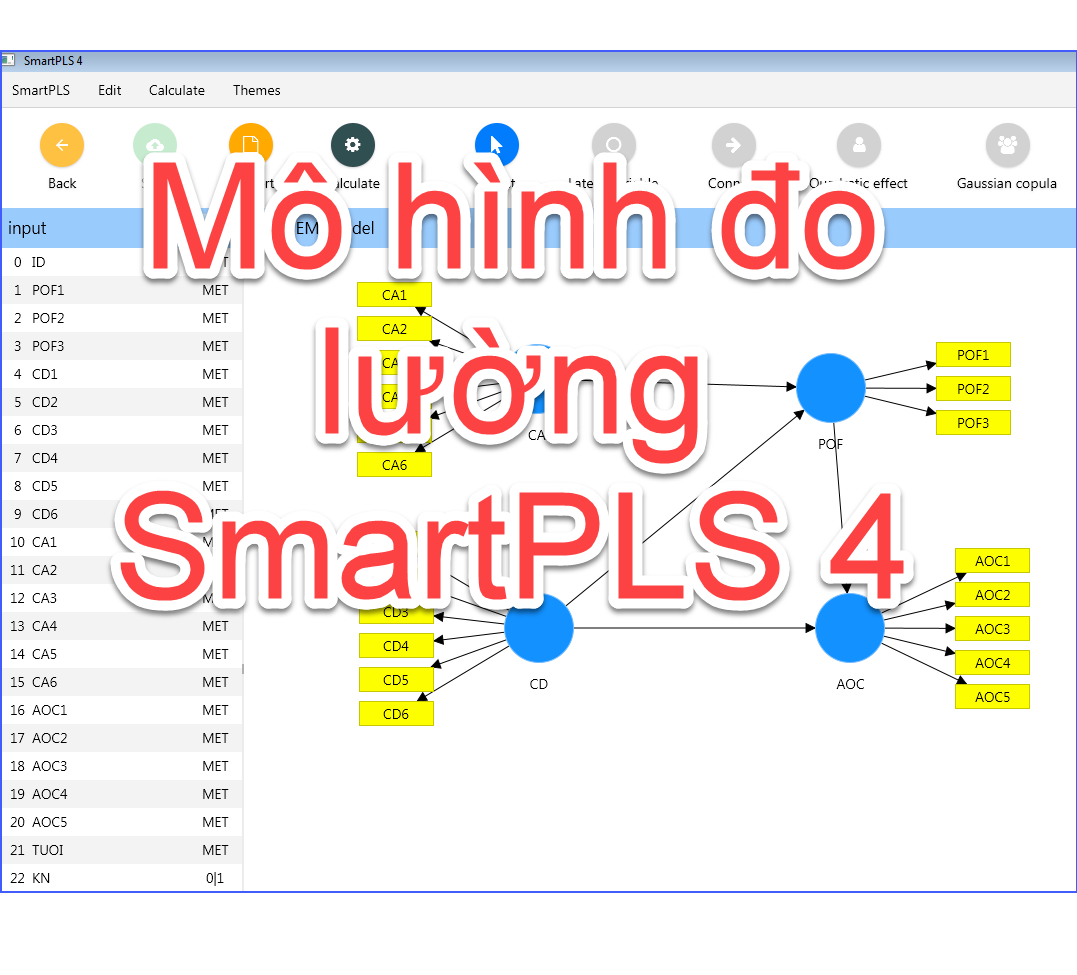
Giới thiệu về mô hình đo lường trong SmartPLS 4 Trong phân tích......
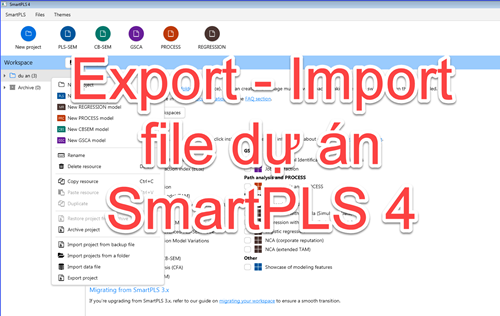
Việc Export – Import file dự án SmartPLS 4 là việc cần làm......
Chỉ số Effect Size f2 là gì? Ngoài hệ số R2 để đánh......
Không biết chạy SPSS? Số liệu không có ý nghĩa thống kê? Dịch......
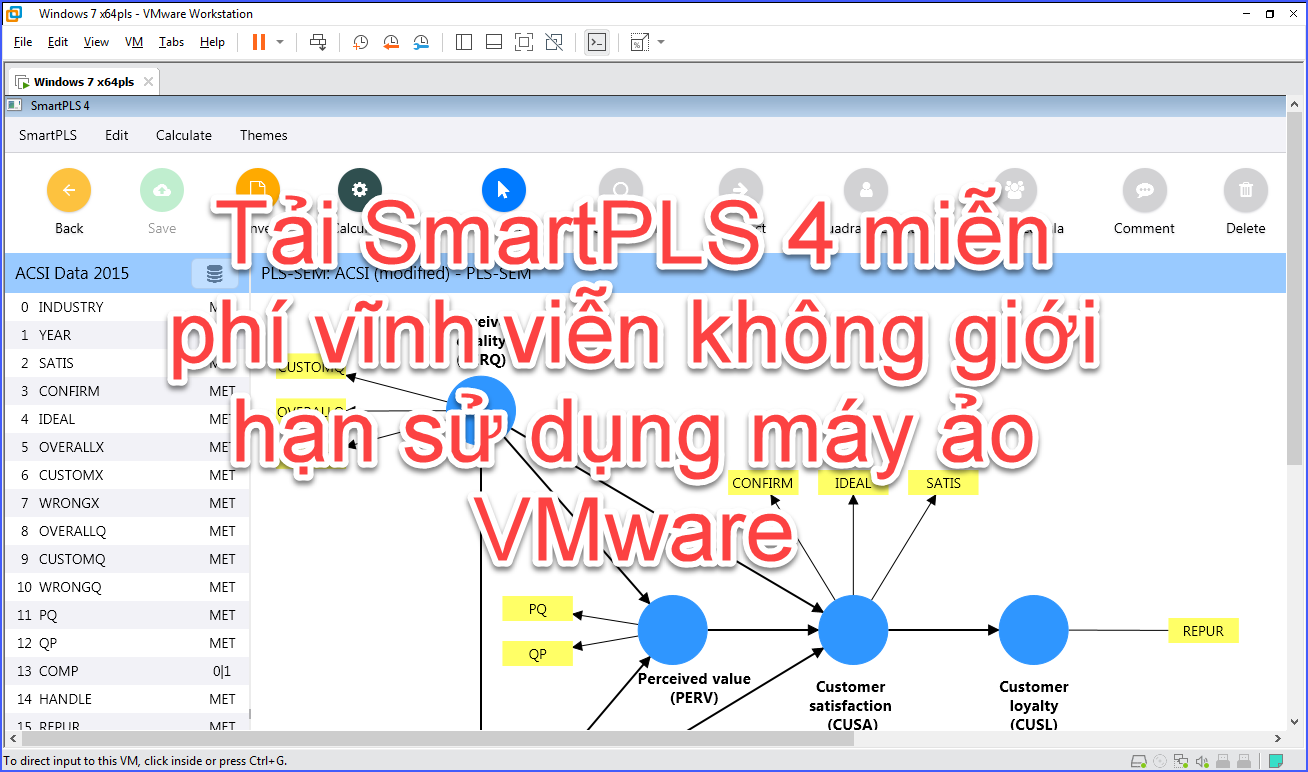
Tại sao sử dụng SmartPLS 4 miễn phí vĩnh viễn cần dùng máy......
3 Comments
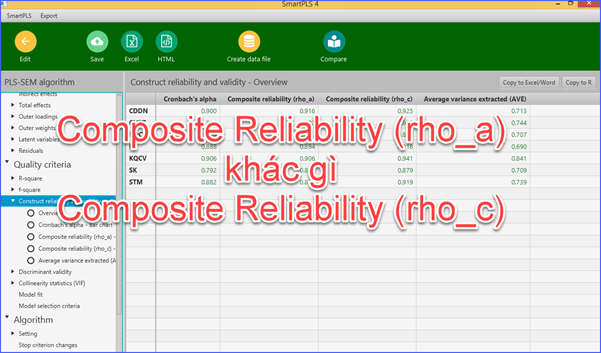
Khi chạy phân tích SmartPLS sẽ có 2 khái niệm độ tin cậy......
Viết luận văn không chỉ đòi hỏi kiến thức chuyên môn mà còn......
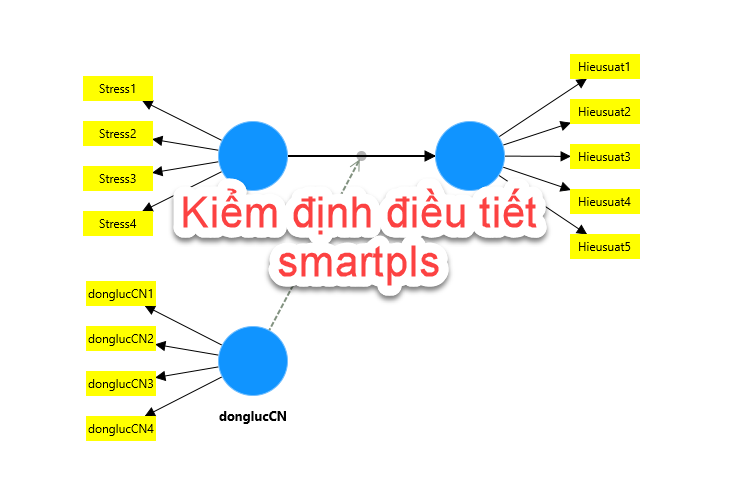
Bài này Thạc Sĩ Khánh và team sẽ giới thiệu về Kiểm định......
Kiểm định trung gian Smartpls là gì? Kiểm định trung gian Smartpls là......
Kiểm định Bootstrap là một phương pháp thống kê quan trọng trong PLS-SEM......
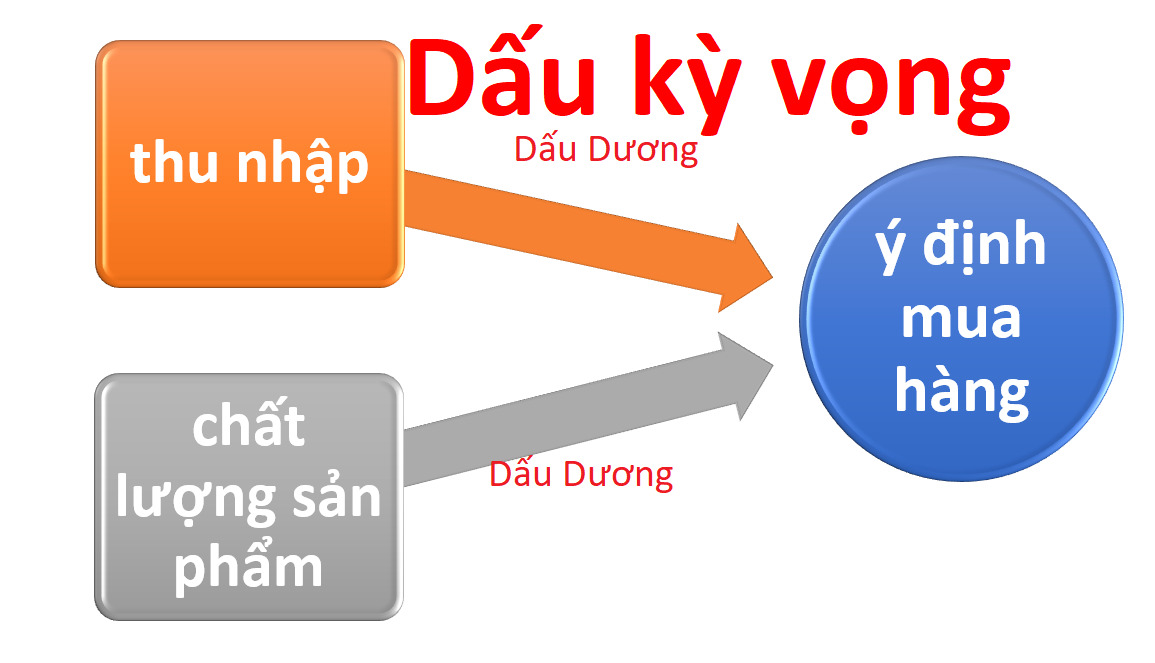
Trong phân tích hồi quy, phát biểu giả thiết thống kê là một......