Không biết chạy SPSS? Số liệu không có ý nghĩa thống kê? Dịch......
Cách hiển thị macro để hiển thị ra các chỉ số model fit......
Thạc sĩ Khánh và nhóm giới thiệu các bạn kiểm định bootstrap, thông......
1 Comment
Nhóm hỗ trợ AMOS giới thiệu đến các bạn cách phân biệt giữa......
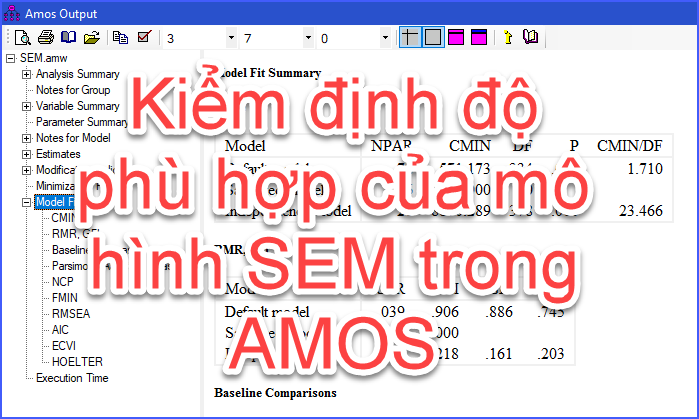
Một trong những chỉ tiêu cần đánh giá khi sử dụng SEM là......
Viết luận văn không chỉ đòi hỏi kiến thức chuyên môn mà còn......
AMOS (Analysis of Moment Structures) là một phần mềm thống kê được sử......
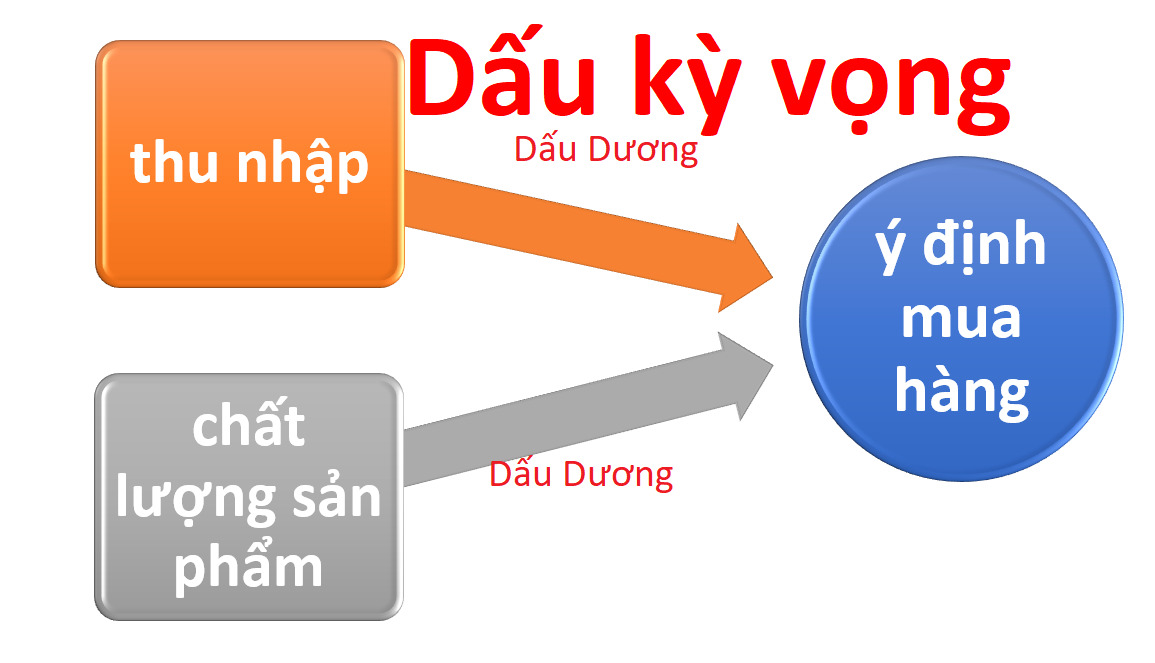
Trong phân tích hồi quy, phát biểu giả thiết thống kê là một......
Chủ nghĩa vị chủng là khuynh hướng con người nhận thức, đánh giá......
Ths Khánh cùng nhóm giới thiệu quy trình dùng Amos và Spss để......
Sau khi chạy phân tích SEM, ta sẽ nhìn vào chỉ số nào......
Tại sao mô hình nghiên cứu cần thiết trong nghiên cứu? Mô hình......