Cơ sở lý thuyết của mô hình mạng (SEM) – Phần 4
Nay nhóm MBA đăng phần thứ 4 loạt bài về mô hình SEM của tác giả Phạm Đức Kỳ – (Nguồn: mba-15.com) để cung cấp thêm kiến thức cho các bạn học viên quan tâm. Loạt bài này gồm 5 phần.
Phần thứ 4: Giới thiệu về phân tích EFA, CFA, ma trận cấu trúc hiệp phương sai, sơ đồ đường path diagram,direct effect, indirect effect
- PHÂN TÍCH NHÂN TỐ KHÁM PHÁ (EFA) VÀ KHẲNG ĐỊNH (CFA)
6.1 Phân tích nhân tố khám phá( EFA) : được dùng đến trong trường hợp mối quan hệ giữa các biến quan sát và biến tiềm ẩn là không rõ ràng hay không chắc chắn. Phân tích EFA theo đó được tiến hành theo kiểu khám phá để xác định xem phạm vi, mức độ quan hệ giữa các biến quan sát và các nhân tố cơ sở như thế nào, làm nền tảng cho một tập hợp các phép đo để rút gọn hay giảm bớt số biến quan sát tải lên các nhân tố cơ sở. Các nhân tố cơ sở là tổ hợp tuyến tính (sơ đồ cấu tạo) của các biến mô tả bằng hệ phương trình sau:
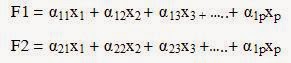
Số lượng các nhân tố cơ sở tùy thuộc vào mô hình nghiên cứu, trong đó chúng ràng buộc nhau bằng cách xoay các vector trực giao nhau để không xảy ra hiện tượng tương quan. Phân tích nhân tố khám phá EFA rất hữu dụng trong bước thực nghiệm ban đầu hay mở rộng kiểm định.
6.2 Phân tích nhân tố khẳng định (CFA): sử dụng thích hợp khi nhà nghiên cứu có sẵn một số kiến thức về cấu trúc biến tiềm ẩn cơ sở. Trong đó mối quan hệ hay giả thuyết (có được từ lý thuyết hay thực nghiệm) giữa biến quan sát và nhân tố cơ sở thì được các nhà nghiên cứu mặc nhiên thừa nhận trước khi tiến hành kiểm định thống kê. Như vậy CFA là bước tiếp theo của EFA nhằm kiểm định xem có một mô hình lý thuyết có trước làm nền tảng cho một tập hợp các quan sát không. CFA cũng là một dạng của SEM. Khi xây dựng CFA, các biến quan sát cũng là các biến chỉ báo trong mô hình đo lường, bởi vì chúng cùng ” tải” lên khái niệm lý thuyết cơ sở.
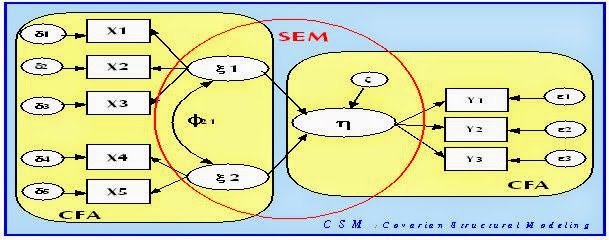
Phương pháp phân tích nhân tố khẳng định CFA chấp nhận các giả thuyết của các nhà nghiên cứu, được xác định căn cứ theo quan hệ giữa mỗi biến và một hay nhiều hơn một nhân tố. Sau đây là một mô hình SEM sử dụng kỹ thuật phân tích CFA:
Hình 13: Mô hình đo lường và mô hình cấu trúc của SEM
X1 = λ11 ξ1 + δ1
X2 = λ22 ξ2 + δ2
X3 = λ31 ξ1 + λ32 ξ2 + δ3,
(ξ i laø caùc nhaân toá chung, Xi laø caùc nhaân toá xaùc ñònh)
Trong đó: λ là các hệ số tải, các nhân tố chung ξ i có thể có tương quan với nhau, các nhân tố xác định Xi cũng có thể tương quan với nhau. Phương sai của một nhân tố xác định là duy nhất.
Phương trình biểu diễn mô hình một cách tổng quát dạng ma trận của x như sau:
x = Λx ξ +δ
Cov(x, ξ) = Σ = E(xx’) = E [(Λx ξ +δ)(Λx ξ +δ)’] = E[(Λx ξ +δ)(Λ’x ξ ‘+δ’)]
= Λx E(ξξ’)Λx’ + ΛxE(ξδ’)Λx’ + E(δ’δ’)
Ñaët : Σ = E(xx’); Φ = E(ξξ’); Θ = E(δδ’)
Vôùi x’; Λx’; ξ ‘; δ’ laàn löôït laø ma traän chuyeån vò cuûa ma traän x; Λx; ξ ;δ.
Cuối cùng phương trình Covariance được viết gọn như sau:
Σx = Λx Φξ Λ’x + Θx
Tương tự đối với phương trình dạng ma trận của y và ma trận Covariance:
y = Λyη + ε
Σy = Λy Φη Λ’y + Θy
- MA TRẬN CẤU TRÚC CỦA MÔ HÌNH MẠNG (CSM) (hình 14)
Đơn vị phân tích trong mô hình mạng (SEM) là các ma trận phương sai (VAR) hay hiệp phương sai(COV). Tổng quát thủ tục SEM xác định một ma trận lý thuyết hàm ý (ma trận tương quan kỳ vọng) bởi mô hình nghiên cứu. Do vậy các đầu vào cần thiết của SEM là các dữ liệu thô hay moment mẫu được tính từ dữ liệu ( VAR, COV, hệ số tương quan hay các moment khác) và mô hình đang được đánh giá. Mô hình bao gồm một tập hợp các phương trình đề xuất, với vài thông số ban đầu được gán giá trị cố định và các thông số cần ước lượng (mean, variance, regression weight..)
Mục đích của ma trận VAR và COV trong SEM dùng để xác định các mối quan hệ giữa các phần tử trong mô hình bằng cách ước lượng ma trận tương quan kỳ vọng (tổng thể), so sánh với ma trận tương quan của dữ liệu quan sát (mẫu) thông qua kiểm định Chi square. Sự khác biệt giữa tương quan “ước lượng” và tương quan “quan sát” của hai ma trận này thể hiện trong sự thay đổi giá trị Chi square, nó chỉ ra mức độ phù hợp của mô hình với dữ liệu như thế nào (Chi square không có ý nghĩa (p > 0.05) biểu thị một sự phù hợp tốt). Kiểm định Chi square bao gồm cả tương quan của biến quan sát và tương quan kỳ vọng
Hình 14: Mô hình cấu trúc hiệp phương sai

(CSM- Covariance Structural Modeling)
SEM giả định các thành phần sai số ngẫu nhiên trong mô hình có phân phối chuẩn đa biến ( biểu diễn bằng hình ellipse). Với giả định này cho phép dùng phương pháp ML ( Maximum Likelihood) để ước lượng các hệ số trong mô hình. Trong trường hợp các điều kiện ước lượng ML không thỏa mãn, như các biến phân loại (categorical) chẳng hạn thì phải sử dụng phương pháp ước lượng LS. Tất cả các phương pháp ước lượng trong SEM đều đòi hỏi kích thước mẫu lớn.
Ngoài ra các thành phần ngẫu nhiên trong SEM cũng đòi hỏi sai số đo lường của x (hay của y), tức là δ (hay ε) không tương quan với các biến tiềm ẩn độc lập ξ (hay phụ thuộc η). Đồng thời sai số phương trình trong mô hình cấu trúc giữa các biến tiềm ẩn độc lập và tiềm ẩn phụ thuộc thì không tương quan với các sai số đo lường của các biến chỉ báo quan sát ( x và y), tức là ζ không được tương quan với δ (hay ε).
- SƠ ĐỒ ĐƯỜNG (Path Diagram)
Nếu cấu trúc của một mô hình chỉ biểu thị bằng các phương trình thì rất phức tạp và khó hiểu. Để đơn giản hoá và thuận tiện trong phân tích, người ta biểu diễn mối quan hệ các nhân tố dưới dạng sơ đồ đường của cả mô hình đo lường và mô hình cấu trúc.
Khái niệm biến ngoại sinh ξ trong mô hình còn gọi là biến nguồn hay biến độc lập vì nó không chịu tác động của biến dự báo hay biến nào khác trong mô hình. Khái niệm biến nội sinh η được dự báo bởi một hay nhiều khái niệm khác.
- PHÂN TÍCH SƠ ĐỒ ĐƯỜNG (Path Analysis)
Phân tích sơ đồ đường hay còn gọi là mô hình nhân quả, tập trung vào việc khảo sát mạng lưới quan hệ giữa các biến đo lường, mối quan hệ nhân quả giữa hai hay nhiều biến, cường độ của các quan hệ trực tiếp và gián tiếp, có thể phân tích cả các quan hệ trung gian (X->Y->Z).
Phương trình cấu trúc :
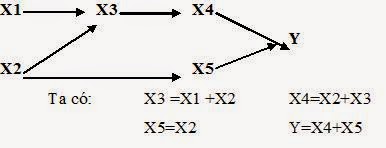
Trong phân tích sơ đồ đường các phần tử biến có quan hệ ảnh hưởng trực tiếp và gián tiếp nhau. Trong sơ đồ nhân quả trên ta có:
Ảnh hưởng trực tiếp : X3 gồm ảnh hưởng của X1 và X2,
X4 gồm ảnh hưởng của X2 và X3,
X5 chỉ ảnh hưởng trực tiếp bởi X2
Y gồm ảnh hưởng của X4 và X5
Ảnh hưởng gián tiếp:
Là ảnh hưởng của một biến thông qua một biến khác, ví dụ:
X1 ảnh hưởng lên X4 thông qua X3
X1 ảnh hưởng lên Y một cách gián tiếp thông qua X3 và X4.
Ảnh hưởng giữa các biến biểu thị bằng các hệ số tương quan. Toàn bộ các ảnh hưởng giữa các biến trong mô hình SEM tạo nên ma trận tương quan cấu trúc:
r13 = p31 ; r23 = p32 ; r14 =p43 . p31
r24 =p43. p32 + p42; r25 = p52
ry = py4.p42 + py4 . p43. p32 + py5.p52
Quy tắc: Tương quan cấu trúc giữa hai biến thì bằng tổng các tác động trực tiếp và gián tiếp có khả năng xảy ra.
Giả sử có ma trận tương quan của các biến quan sát X1, X2 và X3 như sau:
X1 X2 X3
X1 1.0 r12 r13
X2 1.0 r23
X3 1.0
Giả thiết một mô hình cấu trúc (M1) dùng để kiểm định là :
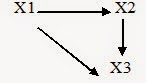
Mô hình này được biểu diễn bằng các phương trình sau
ŕ12 = p21 (p: heä soá hoài quy rieâng phaàn chuaån hoùa)
ŕ13 = p31 +p32. p21 (ảnh hưởng trực tiếp của X1 lên X3 cộng với ảnh hưởng gián tiếp qua X2)
ŕ23 = p32 + p31. p21 (ảnh hưởng trực tiếp của X2 lên X3 cộng với ảnh hưởng của X1 lên X3 và X2)
ŕij biểu diễn tương quan “tái cấu trúc” hay tương quan “ước lượng” trên cơ sở mô hình lý thuyết trên đây. Hệ số hồi quy có thể ước lượng bằng phương pháp hồi quy đa biến trên cơ sở mô hình đã cho và có thể dùng để “tái cấu trúc lại” ma trận tương quan.
- Tương quan của các quan sát bằng dữ liệu:
X1 X2 X3
X1 1.0 r 12(o) r13(o)
X2 1.0 r23(o)
X3 1.0
- Tương quan tái cấu trúc trên cơ sở mô hình sơ đồ đường:
X1 X2 X3
X1 1.0 ŕ12 (e) ŕ13(e)
X2 1.0 ŕ23(e)
X3 1.0
So sánh các phần tử của hai ma trận tương quan này càng giống nhau thì giá trị Chi square càng nhỏ.
![]()
Lưu ý rằng mỗi mô hình thay thế có một tập tương quan kỳ vọng khác nhau làm cho mô hình tốt hơn hoặc xấu đi. Giả sử mô hình lý thuyết ở trên bây giờ là (M2)
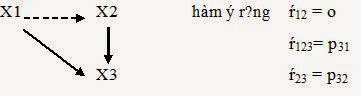
Hầu hết các mô hình nhân quả đều tiến hành so sánh để chọn ra mô hình phù hợp nhất. Mỗi mô hình có một giá trị Chi square ứng với số bậc tự do nhất định. Hai mô hình M1 và M2 giống nhau nhưng M2 bỏ đi mối quan hệ X1 và X2. Ý nghĩa của sự tăng /giảm độ phù hợp trong trường hợp này là :với df = df1 – df2 (hay còn xác định bằng chỉ số sự thay đổi của Chi square trên một bậc tự do)
Mỗi đường biểu diễn một quan hệ giữa hai biến thì tương ứng với một giả thuyết nghiên cứu, không được kiểm định để xác định hướng. Phân tích nhân quả là phân tích các tập hợp con của mô hình SEM như hình dưới đây:
Hình 15: Mô hình đo lường con và sự kết hợp của chúng trong mô hình cấu trúc của SEM

Phân tích nhân quả chỉ đề cập đến các biến đo lường, là sự mở rộng của hồi quy, có tính đồng thời và dùng độ đo tổng hợp.
Phân tích nhân quả là kỹ thuật xác định quan hệ trực tiếp và gián tiếp giữa các biến số, là các liên kết giả thuyết giữa các biến ngoại sinh và biến nội sinh, là hiệu ứng trực tiếp hay chính là hệ số hồi quy. Liên kết gián tiếp (hay hiệu ứng gián tiếp) qua biến trung gian bằng tích của hai hay nhiều hệ số hồi quy. Hệ số nhân quả bằng hệ số tương quan hay hồi quy (thường chuẩn hoá) liên kết các biến số.Nếu chỉ có một liên kết giữa hai biến số, hệ số nhân quả bằng hệ số tương quan. Ý nghĩa của hệ số nhân quả chính là tỷ số giới hạn CR = β/SEβ = Z-Statistic; CR > 1.96 để có ý nghĩa tại p=0.05 hay CR = 2.5 tại mức ý nghĩa 0.01.
Ngoài ra nhóm hotrospss@gmail.com có các dịch vụ sau:
– Tư vấn mô hình/bảng câu hỏi/ traning trực tiếp về phân tích hồi quy, nhân tố, cronbach alpha… trong SPSS, và mô hình SEM, CFA, AMOS
– Thu thập/Xử lý số liệu khảo sát để chạy ra kết quả có ý nghĩa thống kê.
- Common method bias là gì?
- Phép kiểm định nào phù hợp khi so sánh quan hệ giữa biến định tính với định tính, định tính với định lượng
- Lịch sử hình thành của SEM Structural Equation Modeling
- So sánh sự khác nhau giữa hệ số beta đã chuẩn hóa và chưa chuẩn hóa khi phân tích hồi quy
- Macro hiển thị các chỉ số trong AMOS