Nhiều bài nghiên cứu rơi vào tình huống tưởng như đã “xong việc”: dữ liệu thu thập đủ mẫu, SPSS chạy ra kết quả, bảng biểu đầy đủ. Nhưng đến khi nộp cho giảng viên hướng dẫn thì bị trả về với một câu rất ngắn: “Dữ liệu có vấn đề, xem lại.” Lúc này, có thể sẽ hoang mang vì không hiểu mình đã sai ở đâu, trong khi SPSS không báo lỗi gì cả. Thực tế, SPSS chỉ là công cụ xử lý số liệu, nó không có trách nhiệm đánh giá chất lượng dữ liệu. Nếu dữ liệu khảo sát bị lệch thiếu trùng, thì kết quả phân tích dù có “đẹp” đến đâu cũng rất dễ bị hội đồng bác bỏ.
Nên hôm nay ThS Khánh và team giới thiệu đến một số kinh nghiệm liên quan dữ liệu khảo sát bị lệch thiếu trùng nhé.
Dữ liệu bị thiếu – missing data
Vấn đề đầu tiên thường gặp là dữ liệu bị thiếu (missing data). Thiếu dữ liệu không phải lúc nào cũng nguy hiểm, nhưng nguy hiểm ở chỗ nhiều người không phân biệt được thiếu ở mức nào thì chấp nhận được, mức nào thì không. Khi một vài giá trị bị thiếu ngẫu nhiên, rải rác và chiếm tỷ lệ nhỏ, dữ liệu vẫn có thể xử lý tiếp. Như ảnh dưới là 4 giá trị bị thiếu
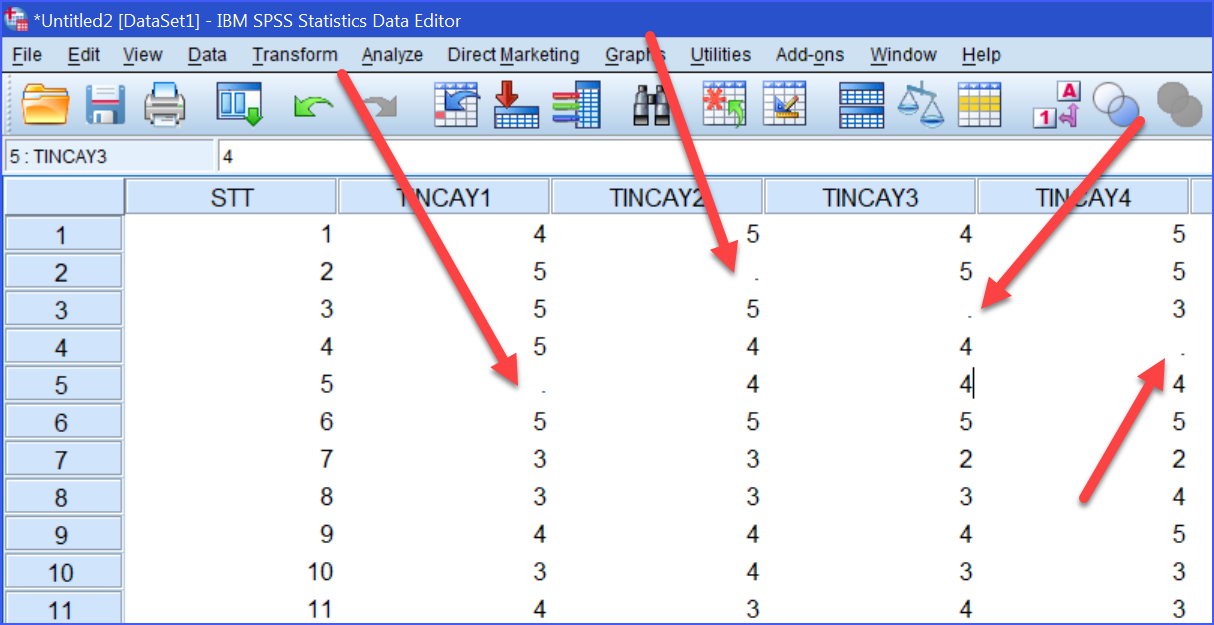
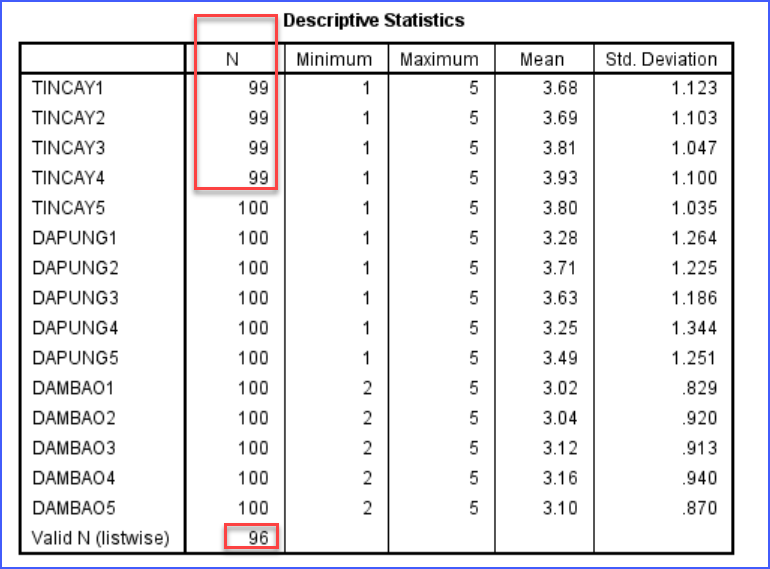
Tuy nhiên, nếu một biến quan trọng bị thiếu quá nhiều, hoặc tình trạng thiếu tập trung vào một nhóm đối tượng cụ thể (ví dụ chỉ sinh viên năm cuối bỏ trống, chỉ nhóm thu nhập thấp không trả lời), thì bản chất mẫu nghiên cứu đã bị méo. Trong những trường hợp này, Cronbach’s Alpha vẫn có thể cao, EFA vẫn có thể chạy, nhưng kết quả không còn đại diện cho tổng thể nghiên cứu. Đây là lỗi rất khó phát hiện nếu chỉ chăm chăm nhìn vào bảng output của SPSS. Tuy nhiên khi dùng thống kê mô tả có thể biết được biến nào bị thiếu, và tổng số mẫu hợp lệ còn lại là bao nhiêu.
Dữ liệu bị lệch 1 bên
Nhiều bộ dữ liệu khảo sát có xu hướng “dồn về một phía”, đặc biệt là khi người trả lời chọn gần như toàn bộ “đồng ý” hoặc “rất đồng ý”. Nguyên nhân có thể đến từ cách thiết kế câu hỏi quá an toàn, người trả lời làm cho xong, hoặc khảo sát không đủ phân hóa. Khi dữ liệu bị lệch mạnh, các chỉ số trung bình trở nên kém ý nghĩa( vì khi người ta chọn mức 4-5 thì điểm trung bình toàn cao), trong khi nhiều phương pháp phân tích lại ngầm giả định dữ liệu phân phối tương đối chuẩn. Kết quả là mô hình hồi quy vẫn cho hệ số có ý nghĩa thống kê, nhưng khi giải thích thì rất gượng gạo và thiếu sức thuyết phục. Giảng viên có kinh nghiệm nhìn vào mô tả dữ liệu là nhận ra ngay vấn đề này.
Dữ liệu bị trùng
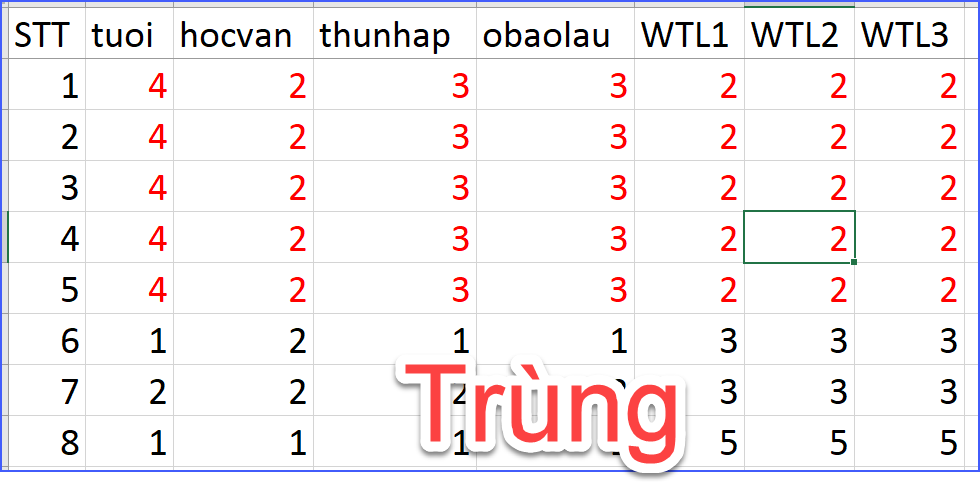
Trùng có thể xảy ra khi một người trả lời nhiều lần, khi dữ liệu bị copy–paste, hoặc khi thu thập khảo sát online mà không kiểm soát tốt. SPSS không tự động cảnh báo dữ liệu trùng nếu người làm không chủ động kiểm tra. Khi dữ liệu trùng tồn tại, kết quả phân tích sẽ bị thiên lệch theo những quan sát lặp lại đó, làm sai lệch ước lượng và giảm giá trị khoa học của nghiên cứu. Đây cũng là lỗi mà hội đồng chấm luận văn rất hay soi, đặc biệt trong các đề tài định lượng.
Vậy có nên tiếp tục chạy SPSS khi dữ liệu gặp các vấn đề trên hay không? Câu trả lời là không nên. Nếu dữ liệu thiếu nhiều ở các biến cốt lõi, phân phối quá lệch nhưng vẫn cố dùng các phương pháp giả định chuẩn, hoặc tồn tại mẫu rác, mẫu trùng mà chưa xử lý, thì việc chạy tiếp chỉ là cố hoàn thành hình thức chứ không tạo ra kết quả nghiên cứu có giá trị. SPSS sẽ không ngăn bạn làm điều đó, nhưng người chấm luận văn thì có.
Trong những trường hợp này, việc đúng cần làm là tạm dừng phân tích, quay lại kiểm tra chất lượng dữ liệu đầu vào, làm sạch dữ liệu, loại những mẫu không hợp lệ, xem xét giữ hay loại biến quan sát. Rất nhiều trường hợp không cần thu thập lại dữ liệu từ đầu, nhưng bắt buộc phải xử lý và hiệu chỉnh đúng cách. Nếu bỏ qua bước này, bạn có thể tiết kiệm được vài ngày chạy SPSS, nhưng lại phải trả giá bằng việc sửa luận văn nhiều lần, thậm chí không kịp bảo vệ.
Nếu bạn đã có dữ liệu, đã chạy SPSS nhưng kết quả khiến chính bạn cũng thấy “không ổn”, hoặc đã bị giảng viên nhắc nhở về chất lượng dữ liệu, thì đừng cố chạy thêm. Điều quan trọng không phải là chạy cho xong, mà là đảm bảo dữ liệu đủ điều kiện để phân tích và đủ sức thuyết phục khi bảo vệ.
Bạn nên đọc thêm: Dữ liệu thế này có làm luận văn được không? và Vì sao Cronbach’s Alpha cao vẫn sai? Hiểu đúng để không rớt luận văn để hiểu rõ hơn mối liên hệ giữa dữ liệu đầu vào và kết quả phân tích.
Nếu bạn không chắc dữ liệu của mình còn sử dụng được hay không, có cần xử lý lại hay nên dừng để làm lại từ đầu, bạn có thể cân nhắc việc kiểm tra và xử lý số liệu trước khi phân tích tiếp. Hãy liên hệ ThS Khánh để được tư vấn nhé.
- Hai cách tiếp cận để kiểm định biến điều tiết: kiểm định dạng interaction effect và dạng multi group. Tại sao nên dùng multigroup hơn là interaction?
- Bộ dữ liệu sách Phân tích dữ liệu nghiên cứu với SPSS – Hoàng Trọng
- Phân tích phương sai một yếu tố anova
- Giá trị hội tụ và giá trị phân biệt trong SPSS là gì?
- Tải phần mềm SPSS 20 full miễn phí đủ tính năng