Với bộ số liệu như sau thì phải sử dụng Repeated Measures ANOVA
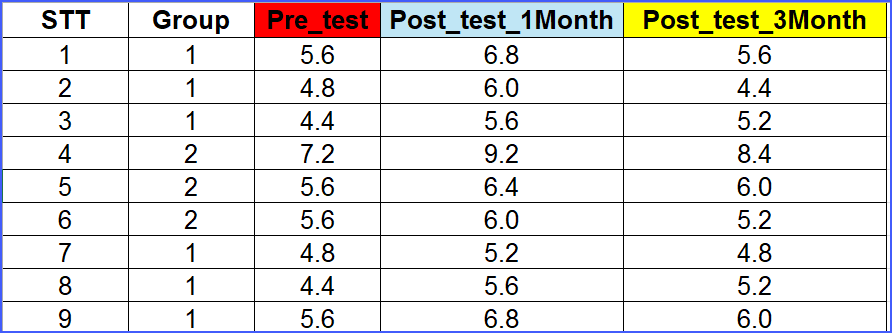
Vì sẽ có 3 nhóm giá trị: điểm kiểm tra trước khi áp dụng phương pháp, điểm kiểm tra trước khi áp dụng phương pháp 1 tháng, điểm kiểm tra trước khi áp dụng phương pháp 3 tháng. Nếu chỉ đơn thuần là so sánh 2 thời điểm thì Paired Sample T-Test đã giải quyết được, nhưng nếu so sánh 3 thời điểm thì T-Test không thể làm được.
Vì sao không dùng Paired Sample T-Test mà phải dùng Repeated Measures ANOVA?
Một câu hỏi thường gặp khi phân tích dữ liệu đo lặp là: nếu đã có thể dùng Paired Sample T-Test để so sánh trước và sau, vậy tại sao lại cần đến Repeated Measures ANOVA?
Sự khác biệt nằm ở số lượng lần đo. Paired Sample T-Test chỉ phù hợp khi nghiên cứu có hai lần đo trên cùng một nhóm đối tượng. Ví dụ, đo mức độ hài lòng của khách hàng trước và sau khi sử dụng dịch vụ, hoặc đo huyết áp của bệnh nhân trước và sau điều trị. Khi chỉ có hai thời điểm, Paired T-Test có thể xác định liệu có sự thay đổi có ý nghĩa thống kê hay không.
Tuy nhiên, trong nhiều nghiên cứu thực tế, một đối tượng có thể được theo dõi ở nhiều thời điểm khác nhau. Ví dụ, đánh giá hiệu quả của một chương trình đào tạo bằng cách đo kết quả của sinh viên trước khóa học, sau 1 tháng và sau 3 tháng. Nếu sử dụng Paired Sample T-Test, nhà nghiên cứu sẽ phải thực hiện nhiều lần so sánh từng cặp thời điểm (trước – sau 1 tháng, trước – sau 3 tháng, sau 1 tháng – sau 3 tháng).
Vấn đề là khi thực hiện quá nhiều phép kiểm định riêng lẻ, xác suất xuất hiện sai lầm loại I (kết luận có sự khác biệt trong khi thực tế không có) sẽ tăng lên. Ngoài ra, việc chạy nhiều lần T-Test cũng khiến quá trình phân tích trở nên rời rạc, khó đánh giá được sự thay đổi tổng thể qua các thời điểm.
Repeated Measures ANOVA được thiết kế để giải quyết vấn đề này. Phương pháp này cho phép so sánh đồng thời nhiều lần đo của cùng một nhóm đối tượng trong một mô hình duy nhất. Thay vì kiểm tra từng cặp riêng lẻ, Repeated Measures ANOVA trước tiên đánh giá xem có tồn tại sự khác biệt tổng thể giữa các thời điểm hay không. Nếu kết quả có ý nghĩa thống kê, nhà nghiên cứu mới thực hiện các phân tích Pairwise Comparisons để xác định cụ thể thời điểm nào khác biệt với thời điểm nào.
Có thể hiểu đơn giản, nếu nghiên cứu chỉ có 2 thời điểm thì dùng Paired Sample T-Test là phù hợp. Nhưng khi có từ 3 thời điểm đo trở lên trên cùng một nhóm đối tượng, Repeated Measures ANOVA sẽ là lựa chọn đúng hơn vì nó kiểm soát tốt hơn sai số thống kê và phản ánh được sự thay đổi theo thời gian.
Repeated Measures ANOVA là gì?
Repeated Measures ANOVA là một kỹ thuật thống kê dùng để so sánh sự khác biệt trung bình của cùng một nhóm đối tượng khi được đo nhiều lần trong các điều kiện hoặc thời điểm khác nhau. Điểm đặc biệt của phương pháp này là mỗi đối tượng sẽ đóng vai trò như chính đối chứng của họ, giúp giảm sự khác biệt giữa các cá nhân và tăng khả năng phát hiện sự thay đổi theo thời gian.
Ví dụ, một nghiên cứu muốn đánh giá hiệu quả của một chương trình đào tạo kỹ năng mềm. Nhà nghiên cứu đo điểm kỹ năng của 50 sinh viên trước khi học, sau 3 tháng và sau 6 tháng. Vì 50 sinh viên này được đo lặp lại nhiều lần nên dữ liệu có mối liên hệ với nhau. Lúc này, Repeated Measures ANOVA sẽ giúp kiểm tra xem điểm số trung bình có thay đổi đáng kể giữa các thời điểm hay không.
Khi nào nên sử dụng Repeated Measures ANOVA?
Repeated Measures ANOVA thường được sử dụng khi nghiên cứu có một nhóm đối tượng nhưng được quan sát nhiều lần. Đây là điểm khác biệt quan trọng so với One-way ANOVA truyền thống.
Ví dụ, nếu muốn so sánh mức độ hài lòng của khách hàng ở ba cửa hàng khác nhau, dữ liệu được thu thập từ ba nhóm khách hàng riêng biệt thì có thể sử dụng One-way ANOVA. Nhưng nếu cùng một nhóm khách hàng được hỏi trước khi sử dụng dịch vụ, sau một tháng và sau ba tháng thì cần sử dụng Repeated Measures ANOVA.
Một số tình huống phổ biến có thể áp dụng Repeated Measures ANOVA gồm:
- Đo lường sự thay đổi trước và sau can thiệp.
- So sánh kết quả của cùng một nhóm người qua nhiều thời điểm.
- Đánh giá hiệu quả của thuốc hoặc phương pháp điều trị.
- Theo dõi sự thay đổi hành vi, thái độ hoặc nhận thức theo thời gian.
Sự khác nhau giữa ANOVA thường và Repeated Measures ANOVA
Một trong những nhầm lẫn phổ biến khi chạy SPSS là không biết nên chọn ANOVA thông thường hay ANOVA đo lặp.
ANOVA thông thường giả định rằng các nhóm dữ liệu độc lập với nhau. Ví dụ nhóm A là sinh viên năm nhất, nhóm B là sinh viên năm hai và nhóm C là sinh viên năm ba. Mỗi người chỉ xuất hiện một lần trong dữ liệu.
Trong khi đó, Repeated Measures ANOVA sử dụng khi cùng một đối tượng xuất hiện nhiều lần. Ví dụ một sinh viên được đo điểm số trước khóa học, giữa khóa học và cuối khóa học. Các kết quả này có liên quan với nhau nên không thể xem như các nhóm độc lập.
Nếu sử dụng sai phương pháp, kết quả phân tích có thể bị sai lệch và phần giải thích trong luận văn sẽ không chính xác.
Điều kiện để chạy Repeated Measures ANOVA trong SPSS
- Đầu tiên là dữ liệu cần có biến phụ thuộc dạng định lượng. Ví dụ điểm số, mức thu nhập, thời gian hoàn thành, chỉ số đo lường hoặc điểm trung bình thang đo.
- Tiếp theo là các lần đo phải được thực hiện trên cùng một đối tượng. Nếu dữ liệu đến từ các nhóm khác nhau thì không nên dùng Repeated Measures ANOVA.
- Một giả định quan trọng khác là tính cầu phương sai (Sphericity). Đây là điều kiện liên quan đến sự bằng nhau của phương sai giữa các cặp thời điểm đo. Trong SPSS, giả định này thường được kiểm tra thông qua kiểm định Mauchly’s Test of Sphericity.
Nếu kiểm định này có Sig > 0.05 thì giả định Sphericity được chấp nhận. Nếu Sig < 0.05, nhà nghiên cứu cần sử dụng kết quả hiệu chỉnh như Greenhouse-Geisser hoặc Huynh-Feldt.
Cách chạy Repeated Measures ANOVA trong SPSS
Để thực hiện phân tích Repeated Measures ANOVA trong SPSS, ta vào:
Analyze → General Linear Model → Repeated Measures
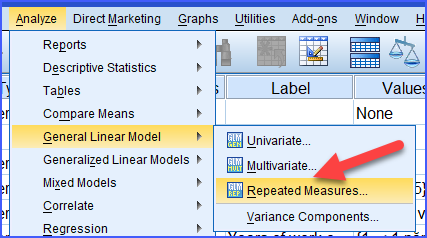
Sau đó khai báo tên của yếu tố đo lặp và số lần đo.
Ví dụ nghiên cứu có ba thời điểm:
- Trước can thiệp
- Sau 1 tháng
- Sau 3 tháng
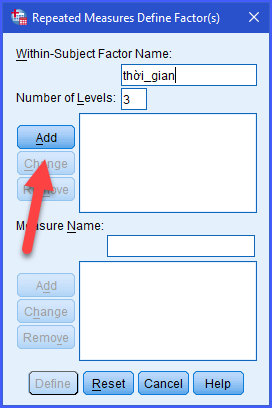
Khi đó có thể đặt Within-Subject Factor Name là “thời_gian” và Number of Levels là 3. Và nhấn ADD
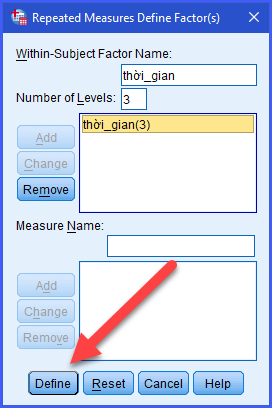
Và ấn Define để khai báo, SPSS sẽ tạo ra các ô tương ứng để đưa biến vào từng thời điểm đo. Sau đó có thể chọn các tùy chọn như kiểm định trung bình, biểu đồ thay đổi theo thời gian và các kiểm định bổ sung.
Kết quả quan trọng nhất cần quan tâm thường nằm ở bảng Tests of Within-Subjects Effects.
Đọc kết quả Repeated Measures ANOVA trong SPSS
Sau khi chạy Repeat Measure ANOVA trong SPSS, ta thấy khá nhiều bảng kết quả như Descriptive Statistics, Mauchly’s Test of Sphericity, Tests of Within-Subjects Effects, Pairwise Comparisons… Nếu không hiểu ý nghĩa từng bảng, rất dễ chọn sai kết quả và đưa ra kết luận không chính xác.
Khi đọc kết quả Repeated Measures ANOVA, không nên nhìn ngay vào Sig trong bảng cuối cùng mà cần kiểm tra lần lượt các bước.
1. Kiểm tra Mauchly’s Test of Sphericity
Bảng đầu tiên cần quan tâm là Mauchly’s Test of Sphericity. Đây là kiểm định dùng để kiểm tra một giả định quan trọng của Repeat Measure ANOVA gọi là Sphericity (tính cầu phương sai).
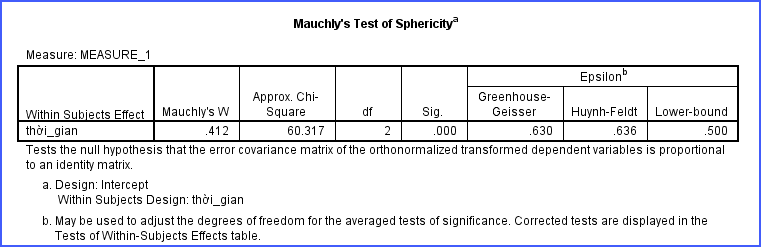
Hiểu đơn giản, giả định này yêu cầu mức độ thay đổi giữa các thời điểm đo phải tương đối đồng đều. Khi nghiên cứu có nhiều hơn 2 lần đo, SPSS cần kiểm tra điều kiện này trước khi đưa ra kết luận cuối cùng.
Trong bảng Mauchly’s Test of Sphericity, cần chú ý cột Sig. Nếu: Sig. > 0.05 Có nghĩa là dữ liệu không vi phạm giả định Sphericity. Khi đó có thể sử dụng dòng Sphericity Assumed trong bảng Tests of Within-Subjects Effects.
Ví dụ: Mauchly’s Test of Sphericity: Sig. = 0.231 Vì 0.231 > 0.05 nên giả định Sphericity được thỏa mãn. Nhà nghiên cứu có thể đọc kết quả ở dòng Sphericity Assumed.
Ngược lại: Sig. < 0.05 Có nghĩa là dữ liệu vi phạm giả định Sphericity. Đây là trường hợp khá thường gặp khi có nhiều lần đo. Ví dụ: Sig. = 0.002 Khi đó không sử dụng dòng Sphericity Assumed mà cần chuyển sang kết quả hiệu chỉnh như:
- Greenhouse-Geisser
- Huynh-Feldt
Thông thường trong luận văn, Greenhouse-Geisser được sử dụng phổ biến hơn khi giả định Sphericity bị vi phạm.
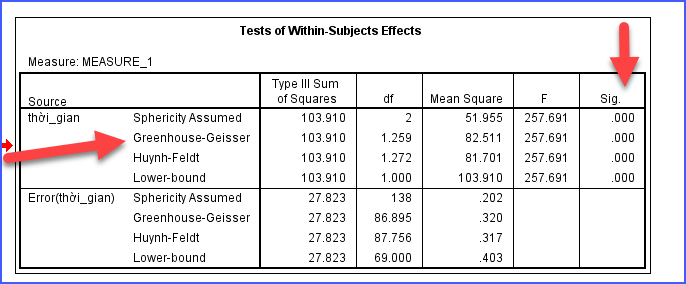
2. Đọc bảng Tests of Within-Subjects Effects
Sau khi biết chọn dòng nào, bước tiếp theo là xem bảng Tests of Within-Subjects Effects.
Đây là bảng quan trọng nhất để trả lời câu hỏi:”Điểm số có thay đổi theo thời gian hay không?”
Trong bảng này cần chú ý cột Sig. Nếu Sig < 0.05, có thể kết luận rằng có sự khác biệt có ý nghĩa thống kê giữa các thời điểm đo.
Điều này có nghĩa là giá trị trung bình của biến phụ thuộc thay đổi theo thời gian.Kết quả Repeat Measure ANOVA có Sig = 0.000 cho thấy sự thay đổi này không phải do ngẫu nhiên mà có ý nghĩa thống kê.
Ngược lại, nếu Sig > 0.05, chưa có bằng chứng cho thấy các thời điểm có sự khác biệt.
3. Xem bảng Descriptive Statistics để biết xu hướng thay đổi
Mặc dù bảng Tests of Within-Subjects Effects cho biết có sự khác biệt hay không, nhưng nó chưa cho biết thay đổi theo hướng nào.
Lúc này cần xem bảng Descriptive Statistics.
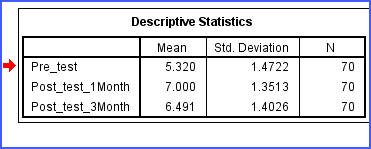
Tuy nhiên, việc tăng hoặc giảm chỉ mang tính mô tả. Muốn biết thay đổi đó có ý nghĩa thống kê hay không vẫn phải dựa vào Sig trong Tests of Within-Subjects Effects.
4. Đọc Pairwise Comparisons (so sánh từng cặp thời điểm)
Nếu Repeat Measure ANOVA cho kết quả có ý nghĩa thống kê (Sig < 0.05), bước tiếp theo cần xem Pairwise Comparisons.
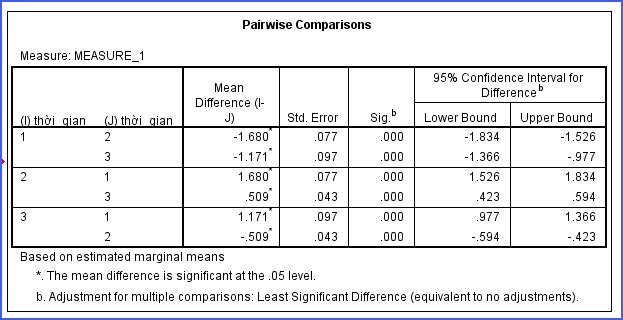
Bảng này giúp trả lời câu hỏi: “Thời điểm nào khác thời điểm nào?”
Tóm tắt quy trình đọc Repeat Measure ANOVA
Khi đọc kết quả, nên đi theo thứ tự: Mauchly’s Test → chọn dòng kết quả phù hợp → Tests of Within-Subjects Effects → xem Sig → Descriptive Statistics → Pairwise Comparisons.

Bạn gặp khó khăn khi xử lý dữ liệu liên quan này cứ liên hệ nhé.
Liên hệ nhóm thạc sĩ Hỗ trợ SPSS.
– SMS, Zalo, Viber:

- Quy tắc loại biến khi phân tích cronbach’s alpha
- Cách mở file SPSS, cách lưu file SPSS, cách nhập dữ liệu từ excel vào SPSS
- Phương sai sai số thay đổi: định nghĩa dễ hiểu nhất, có đồ thị minh họa
- Khi nào không được dùng hồi quy tuyến tính? Những sai lầm khiến kết quả vô giá trị
- So sánh SPSS và EVIEWS khi phân tích hồi quy, cùng một bộ số liệu