Dữ liệu bị đa cộng tuyến phải xử lý sao? Cách nhận biết và khắc phục trong SPSS
Trong quá trình chạy hồi quy tuyến tính bằng SPSS, một trong những lỗi thường gặp nhất là đa cộng tuyến (Multicollinearity). Đây là hiện tượng các biến độc lập có mối tương quan quá mạnh với nhau, làm cho mô hình hồi quy mất ổn định và kết quả phân tích trở nên thiếu tin cậy.
Vậy khi dữ liệu bị đa cộng tuyến phải xử lý sao? Bài viết này sẽ hướng dẫn chi tiết cách nhận biết và xử lý một cách dễ hiểu.
1. Đa cộng tuyến là gì?
Đa cộng tuyến xảy ra khi hai hoặc nhiều biến độc lập trong mô hình hồi quy có mối quan hệ tuyến tính mạnh.
Ví dụ:
- Thu nhập
- Mức chi tiêu
- Khả năng tiết kiệm
Ba biến này thường liên quan chặt chẽ với nhau. Nếu đưa cùng lúc vào mô hình, rất dễ xảy ra đa cộng tuyến.
Khi đó SPSS vẫn chạy ra kết quả, nhưng:
- hệ số Beta có thể bị đảo dấu
- biến có ý nghĩa lý thuyết nhưng Sig lại không có ý nghĩa
- hệ số hồi quy thay đổi mạnh khi thêm hoặc bớt biến
- mô hình khó diễn giải
2. Dấu hiệu nhận biết dữ liệu bị đa cộng tuyến
Cách phổ biến nhất là kiểm tra VIF và Tolerance.
Tiêu chuẩn đánh giá
- VIF < 2 => rất tốt
- VIF < 5 => chấp nhận được
- VIF > 10 => đa cộng tuyến nghiêm trọng
Ngoài ra:
- Tolerance > 0.1 => đạt
- Tolerance < 0.1 => có vấn đề
Trong thực tế luận văn, nhiều giảng viên thường yêu cầu: VIF < 5 để đảm bảo mô hình ổn định.
3. Cách kiểm tra đa cộng tuyến trong SPSS
Vào:Analyze -Regression -Linear
Đưa các biến phù hợp vào
- Dependent: biến phụ thuộc
- Independent: các biến độc lập
Sau đó bấm: Statistics -chọn Collinearity diagnostics
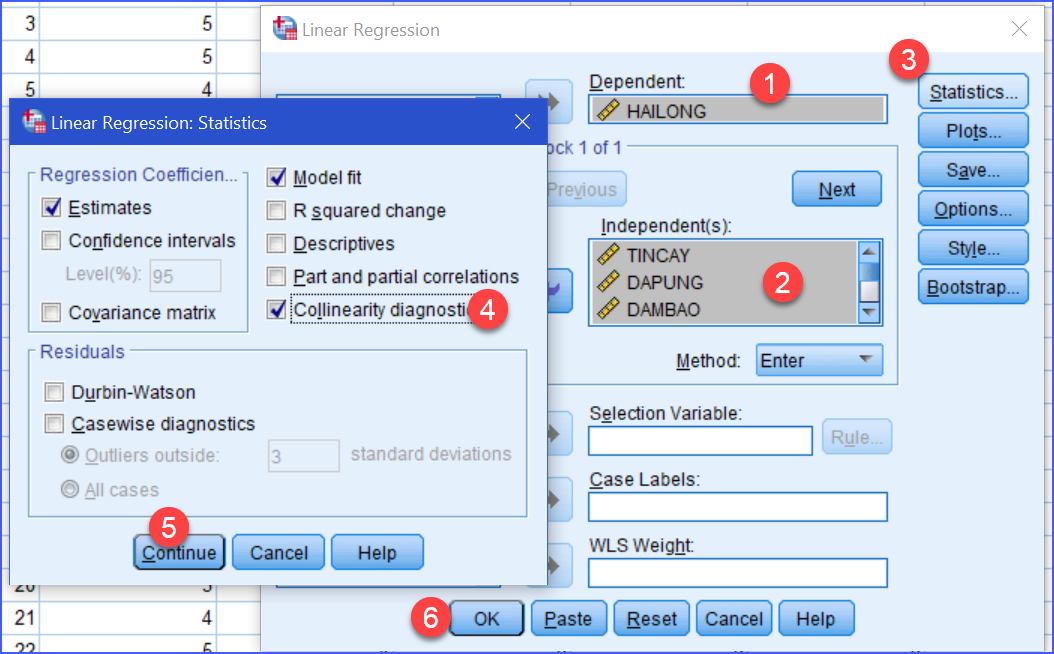
SPSS sẽ trả ra bảng chứa:
Tolerance và VIF
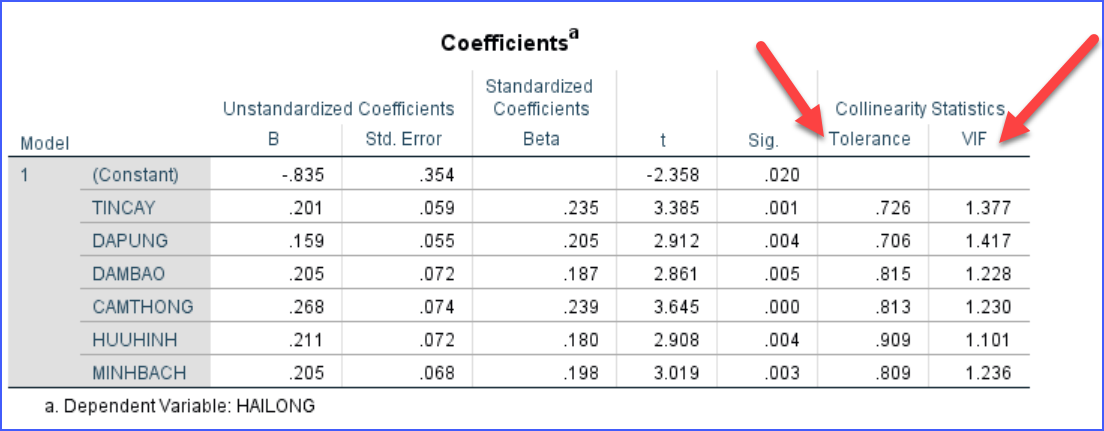
Đây là bảng quan trọng nhất để kiểm tra đa cộng tuyến. Giá trị VIF này dưới 2 là yên tâm rồi nhé.
4. Dữ liệu bị đa cộng tuyến phải xử lý sao?
Đây là phần quan trọng nhất.
Cách 1: Loại bớt nhân tố bị trùng nội dung. Đây là cách xử lý phổ biến nhất.
Ví dụ:
- Chất lượng dịch vụ
- Sự hài lòng về dịch vụ
- Mức độ đánh giá dịch vụ
Nếu nội dung đo lường quá giống nhau, các biến thường tương quan rất mạnh.
Khi đó nên:giữ biến quan trọng hơn về mặt lý thuyết, loại biến ít ý nghĩa hơn. Đây là cách đơn giản và hiệu quả nhất.
Cách 2: Gộp các biến thành một nhân tố
Nếu các biến có ý nghĩa gần giống nhau, có thể gộp thành một nhân tố đại diện sau khi EFA.
Ví dụ:
- Giá cả hợp lý
- Giá cả cạnh tranh
- Giá phù hợp thu nhập
có thể gộp thành nhân tố:Nhận thức về giá
Cách này thường được sử dụng trong nghiên cứu thang đo.
Cách 3: Kiểm tra lại mô hình lý thuyết
Nhiều trường hợp đa cộng tuyến xuất phát từ mô hình nghiên cứu chưa hợp lý.
Ví dụ:đưa đồng thời:
- Sự hài lòng
- Ý định tiếp tục sử dụng
- Lòng trung thành
Vào cùng mô hình để giải thích một biến khác. Trong khi các khái niệm này thường có quan hệ rất gần nhau.
Khi đó cần xem lại: giả thuyết nghiên cứu, có thể bổ sung vai trò trung gian,vai trò điều tiết để sắp xếp mô hình phù hợp hơn.
5. Có nên xóa biến chỉ vì VIF cao?
Không nên xóa biến một cách máy móc. Cần xem xét thêm:
- ý nghĩa lý thuyết
- giả thuyết nghiên cứu
- bản chất thang đo
Có nhiều trường hợp VIF hơi cao nhưng biến lại rất quan trọng về mặt học thuật.
Lúc đó nên cân nhắc giữa: lý thuyết, thống kê thay vì chỉ nhìn vào con số.
6. Kết luận
Khi dữ liệu bị đa cộng tuyến, cách xử lý tốt nhất là:
- kiểm tra VIF
- xác định biến trùng lặp
- loại hoặc gộp biến
- rà soát lại mô hình nghiên cứu
Đa cộng tuyến không phải là lỗi hiếm gặp, đặc biệt trong các nghiên cứu về hành vi, marketing, giáo dục và quản trị.
Nếu anh/chị đang gặp khó khăn khi chạy SPSS và chưa biết xử lý đa cộng tuyến như thế nào cho đúng với luận văn, có thể liên hệ để được hỗ trợ kiểm tra mô hình và xử lý số liệu nhé.
- Sự khác biệt giữa Composite Reliability rho_a và rho_c trong SmartPLS
- Cách hiển thị giá trị Direct Effects,Indirect Effects,Total Effects trong AMOS
- Cách nhận biết mô hình cấu trúc tuyến tính
- Cách phát hiện đa cộng tuyến trong hồi quy nhị phân logit
- Sai lầm khi chạy SPSS khiến chạy xong vẫn rớt luận văn