Cơ sở lý thuyết của mô hình mạng (SEM) – Phần 5
Nay nhóm MBA đăng phần thứ 5, đồng thời cũng là phần cuối, loạt bài về mô hình SEM của tác giả Phạm Đức Kỳ – (Nguồn: mba-15.com) để cung cấp thêm kiến thức cho các bạn học viên quan tâm.
Phần thứ 5 gồm: Kiểm tra độ tin cậy của thang đo ,Mức độ phù hợp của tổng thể mô hình,Kiểm định Chi-Square (χ2),Tỷ số Chi-Square/bậc tự do: χ2 / df ,GFI, AGFI, CFI, NFI , Chỉ số điều chỉnh mô hình (MI – Modification Indices), Kiểm tra ước lượng mô hình bằng phương pháp Boostrap , các công cụ AMOS, LISREL, EQS, MPLUS…
- TÓM TẮT CÁC BƯỚC THỐNG KÊ TRONG SEM
1) Kiểm tra độ tin cậy của thang đo
– Bằng hệ số Cronbach’s Alpha.[Hair et al, 1998, Segar, 1997]
– Ước lượng các hệ số hồi quy và tvalue
– Phân tích nhân tố khẳng định (CFA): thực hiện trên mô hình đo lường để loại các biến có hệ số tải nhân tố tiềm ẩn thấp. Có thể thực hiện kiểm định CFA trên từng mô hình con (Sub Model) trước khi kiểm định mô hình tổng thể(tập hợp các mô hình con để kiểm định đồng thời).
– Thống kê SMC ( Square Multiple Correlation) cho mỗi khái niệm tiềm ẩn ngoại sinh (kết quả phân tích CFA của mô hình đo lường nêu trên), tương tự hệ số R2 trong hồi quy tuyến tính, SMC là phương sai giải thích của mỗi khái niệm tiềm ẩn [Bollen, 1989]
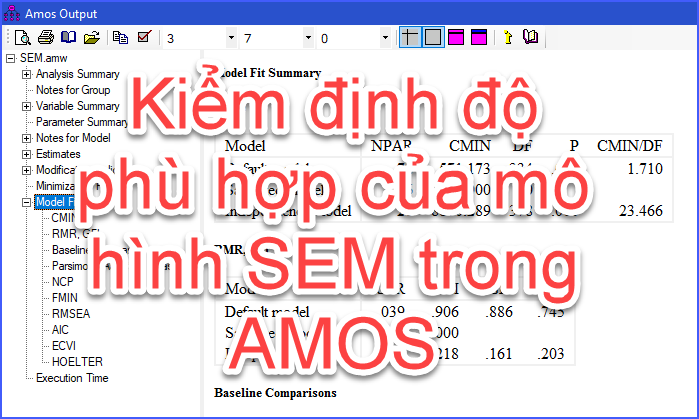
2) Mức độ phù hợp của tổng thể mô hình
Bản chất của mô hình SEM là đòi hỏi các nhà nghiên cứu trước hết thực hiện khai báo các giá trị xuất phát ban đầu được gọi là mô hình giả thiết. Từ mô hình giả thiết, thông qua một chuỗi vòng lặp các chỉ số biến đổi để cuối cùng cung cấp cho nhà nghiên cứu một mô hình xác lập, có khả năng giải thích tối đa sự phù hợp giữa mô hình với bộ dữ liệu thu thập thực tế.
Sự phù hợp của toàn bộ mô hình trên thực tế được đánh giá thông qua các tiêu chí về mức độ phù hợp như sau:
- i) Kiểm định Chi-Square (χ2) :
Biểu thị mức độ phù hợp tổng quát của toàn bộ mô hình tại mức ý nghĩa p-value = 0.05 [Joserkog & Sorbom, 1989]. Điều này thực tế rất khó xảy ra bởi vì χ2 rất nhạy với kích thước mẫu lớn và độ mạnh của kiểm định, nên thực tế người ta dùng chỉ số χ2 /df để đánh giá,
- ii) Tỷ số Chi-Square/bậc tự do: χ2 / df
Cũng dùng để đo mức độ phù hợp một cách chi tiết hơn của cả mô hình. Một số tác giả đề nghị 1 < χ2/df < 3 [Hair et al, 1998]; một số khác đề nghị χ2 càng nhỏ càng tốt [Segar, Grover, 1993] và cho rằng χ2/df < 3:1 [Chin & Todd, 1995] Ngoài ra, trong một số nghiên cứu thực tế người ta phân biệt ra 2 trường hợp : χ2/df < 5(với mẫu N > 200) ; hay < 3 (khi cỡ mẫu N < 200) thì mô hình được xem là phù hợp tốt [Kettinger và Lee,1995].
iii) Các chỉ số liên quan khác:
GFI, AGFI, CFI, NFI, ….. có giá trị > 0.9 được xem là mô hình phù hợp tốt. Nếu các giá trị này bằng 1, ta nói mô hình là hoàn hảo. [Segar, Grover, 1993] & [Chin & Todd, 1995]
GFI: đo độ phù hợp tuyệt đối ( không điều chỉnh bậc tự do) của mô hình cấu trúc và mô hình đo lường với bộ dữ liệu khảo sát.
AGFI: Điều chỉnh giá trị GFI theo bậc tự do trong mô hình.
RMR: Một mặt đánh giá phương sai phần dư của biến quan sát, mặt khác đánh giá tương quan phần dư của một biến quan sát này với tương quan phần dư của một biến quan sát khác.. Giá trị RMR càng lớn nghĩa là phương sai phần dư càng cao, nó phản ánh một mô hình có độ phù hợp không tốt.
RMSEA : là một chỉ tiêu quan trọng, nó xác định mức độ phù hợp của mô hình so với tổng thể.
Trong tạp chí nghiên cứu IS, các tác giả cho rằng chỉ số RMSEA, RMR yêu cầu < 0.05 thì mô hình phù hợp tốt. Trong một số trường hợp giá trị này < 0.08 mô hình được chấp nhận. [Taylor, Sharland, Cronin và Bullard, 1993].
NFI: đo sự khác biệt phân bố chuẩn của χ2 giữa mô hình độc lập (đơn nhân tố, có các hệ số bằng 0) với phép đo phương sai và mô hình đa nhân tố.
NFI = (χ2 null – χ2 proposed) / χ2 null = (χ2 Mo – χ2 Mn) / χ2 Mo
Mo : Mô hình gốc; Mn : Mô hình phù hợp
Giá trị đề nghị NFI > 0.9 [Hair et al, 1998] & [Chin & Todd, 1995]
- iv) Mức xác suất :
Giá trị > .05 được xem là mô hình phù hợp tốt.[Arbuckle và Wothke, 1999; Rupp và Segal, 1989]. Điều này có nghĩa rằng không thể bác bỏ giả thuyết H0 (là giả thuyết mô hình tốt), tức là không tìm kiếm được mô hình nào tốt hơn mô hình hiện tại)
Ngoài ra các quan hệ riêng lẻ cũng được đánh giá tốt dựa trên các mức ý nghĩa thống kê. Tác động của các biến ngoại sinh lên các biến nội sinh và tác động của các biến nội sinh lên các biến nội sinh được đánh giá qua các hệ số hồi quy. Mối quan hệ giữa các biến được biểu thị bằng mũi tên trên mô hình. Chiều mũi tên biểu diễn chiều tác động của biến này lên biến kia. Ứng với một mối quan hệ ta có một giả thuyết tương ứng (như đã trình bày ở phần đầu chương này về các giả thuyết và mô hình nghiên cứu). Trong các nghiên cứu thuộc lĩnh vực khoa học xã hội, tất cả các mối quan hệ nhân quả đề nghị có độ tin cậy ở mức 95% (p = .05)[Cohen,1988]
3) Chỉ số điều chỉnh mô hình (MI – Modification Indices)
Chỉ số điều chỉnh mô hình là chỉ số ước lượng sự thay đổi của χ2 ứng với mỗi trường hợp thêm vào một mối quan hệ khả dĩ (ứng với giảm một bậc tự do). Nếu MI chỉ ra rằng lượng giảm ∆ χ 2 >3.84 (ứng với giảm một bậc tự do), thì cho phép ta đề nghị một mối quan hệ làm tăng độ phù hợp của mô hình. .[Hair et al, 1998]. (xem lại phần 3 – Phân tích sơ đồ đường, so sánh thay đổi χ2 giữa mô hình M1 & M2). Điều này cũng tương tự như đưa từng biến độc lập vào trong mô hình hồi quy tuyến tính. Tuy vậy nhà nghiên cứu nên thận trọng bởi vì mối quan hệ thêm vào mô hình chỉ được xem xét khi nó ủng hộ lý thuyết và không nên cố gắng mọi cách để cải thiện các chỉ số nhằm làm cho mô hình phù hợp hơn [Bullock et al, 1994; Hair et al, 1998].Các chỉ số phù hợp tốt chỉ ra rằng dữ liệu ủng hộ mô hình đề nghị, nhưng chúng không có nghĩa rằng mô hình lựa chọn là chính xác hay là mô hình tốt nhất trong số các mô hình khả thi về mặt lý thuyết. Như vậy sẽ tồn tại một số mô hình với mức độ điều chỉnh độ phù hợp khác nhau, tuỳ theo quan điểm nhà nghiên cứu. Các mô hình này được gọi là các mô hình cạnh tranh.
4) Kiểm tra ước lượng mô hình bằng phương pháp Boostrap
Mô hình cuối cùng cũng như các mô hình phù hợp khác cần thiết phải có bộ dữ liệu độc lập với nhau, hay cỡ mẫu ban đầu khá lớn. Trong phương pháp nghiên cứu định lượng bằng phương pháp lấy mẫu, thông thường chúng ta phải chia mẫu thành 02 mẫu con. Mẫu con thứ nhất dùng để ước lượng các tham số mô hình và mẫu con thứ hai dùng để đánh giá lại:
- Định cỡ mẫu con thứ nhất dùng để khám phá,
- Dùng cỡ mẫu con thứ hai để đánh giá chéo (Cross-Validation)
Chỉ số đánh giá chéo CVI (Cross-Validation Index) đo khoảng cách giữa ma trận Covariance phù hợp trong mẫu con thứ nhất với ma trận Covariance của mẫu. Chỉ số CVI nhỏ nhất cho phép kỳ vọng trạng thái mẫu lặp lại càng ổn định.
Cách khác là lặp lại nghiên cứu bằng một mẫu khác. Hai cách trên đây thường không thực tế vì phương pháp phân tích mô hình cấu trúc thường đòi hỏi mẫu lớn nên việc làm này tốn kém nhiều thời gian, chi phí [Anderson & Gerbing 1998]. Trong những trường hợp như vậy thì Boostrap là phương pháp phù hợp để thay thế[Schumacker & Lomax 1996]. Boostrap la phương pháp lấy mẫu lại có thay thế trong đó mẫu ban đầu đóng vai trò đám đông.
Phương pháp Boostrap thực hiện với số mẫu lặp lại là N lần. Kết quả ước lượng từ N mẫu được tính trung bình và giá trị này có xu hướng gần đến ước lượng của tổng thể. Khoảng chênh lệch giữa giá trị trung bình ước lượng bằng Boostrap và ước lượng mô hình với mẫu ban đầu càng nhỏ cho phép kết luận các ước lượng mô hình có thể tin cậy được.
- CÔNG CỤ THỐNG KÊ ỨNG DỤNG TRONG SEM
Hiện nay có nhiều công cụ phần mềm hỗ trợ quá trình thống kê, phân tích và xác định mô hình SEM như : AMOS, LISREL, EQS, MPLUS… được các nhà nghiên cứu sử dụng rất phổ biến trong các đề tài nghiên cứu. Một trong những công cụ phổ biến nhất là phần mềm AMOS với ưu điểm là : (a) dễ sử dụng nhờ module tích hợp chung với phần mềm phổ biến là SPSS và (b) dễ dàng xây dựng các mối quan hệ giữa các biến, nhân tố (phần tử mô hình) bằng trực quan hình học nhờ chức năng AMOS Graphics. Kết quả được biểu thị trực tiếp trên mô hình hình học, nhà nghiên cứu căn cứ vào các chỉ số để kiểm định các giả thuyết, độ phù hợp của tổng thể mô hình một cách dễ dàng, nhanh chóng. Minh họa cho phương pháp phân tích dữ liệu sử dụng công cụ AMOS có thể tham khảo nghiên cứu của tác giả.
Ngoài ra nhóm hotrospss@gmail.com có các dịch vụ sau:
– Tư vấn mô hình/bảng câu hỏi/ traning trực tiếp về phân tích hồi quy, nhân tố, cronbach alpha… trong SPSS, và mô hình SEM, CFA, AMOS
– Thu thập/Xử lý số liệu khảo sát để chạy ra kết quả có ý nghĩa thống kê.