Tình huống xấu sau khi hoàn thành khảo sát, nhập dữ liệu và chạy mô hình trên SPSS, SmartPLS hoặc AMOS thì kết quả lại không giống với giả thuyết ban đầu, chạy model không đúng giả thuyết. Biến đáng lẽ phải tác động tích cực thì lại không có ý nghĩa thống kê, biến được kỳ vọng quan trọng lại bị loại, thậm chí có trường hợp hệ số tác động bị ngược chiều so với mô hình nghiên cứu đề xuất.
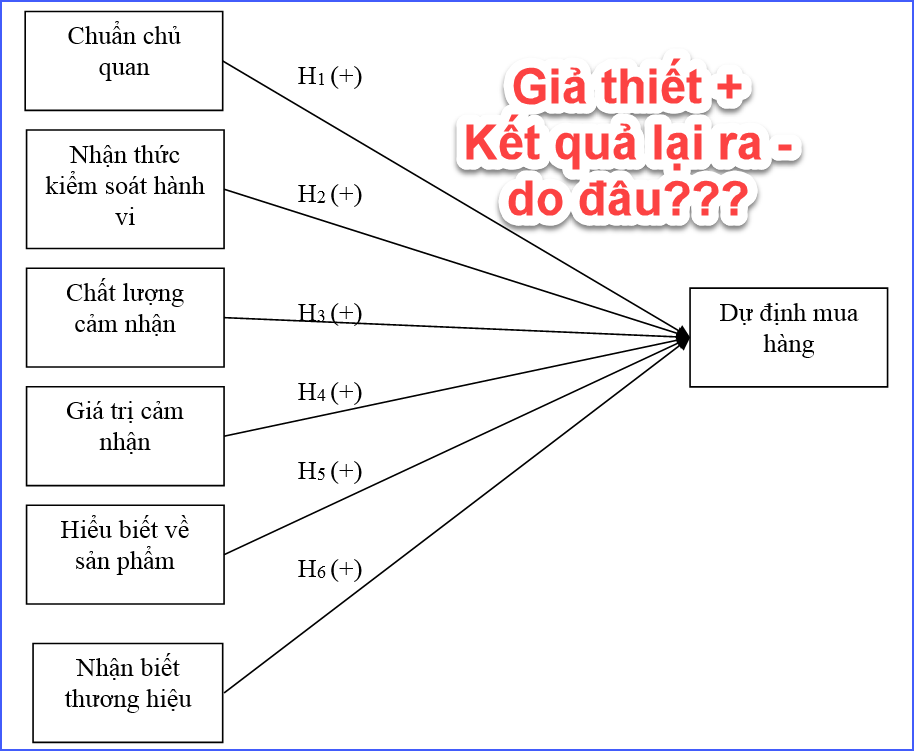
Ví dụ, nghiên cứu đặt giả thuyết rằng “CHUẨN CHỦ QUAN có tác động tích cực đến DỰ ĐỊNH MUA HÀNG”, nhưng khi chạy hồi quy lại cho kết quả Sig > 0.05 hoặc hệ số Beta âm. Lúc này nhiều người nghĩ rằng dữ liệu bị sai hoặc phần mềm chạy sai, nhưng thực tế đây là vấn đề khá phổ biến trong nghiên cứu định lượng.
Chạy model không đúng giả thuyết không có nghĩa là chắc chắn nghiên cứu thất bại. Ta cần tìm hiểu nguyên nhân nằm ở dữ liệu, thang đo, mô hình nghiên cứu. Từ đó có hướng xử lý thích hợp. Hôm nay ThS Khánh sẽ bàn về vấn đề này cùng với bạn nhé.
Vì sao chạy model không đúng giả thuyết ban đầu?
Giả thuyết chỉ là một dự đoán cần được kiểm chứng bằng dữ liệu thực tế. Nên mình không được nghĩ rằng đã xây dựng giả thuyết từ lý thuyết thì kết quả bắt buộc phải giống như kỳ vọng.
Trong nghiên cứu khoa học, việc giả thuyết không được chấp nhận là chuyện bình thường. Dữ liệu thu thập từ thực tế có thể cho thấy mối quan hệ giữa các biến yếu hơn dự kiến hoặc hoàn toàn không tồn tại trong bối cảnh nghiên cứu cụ thể.
Ví dụ, nhiều bài nghiên cứu trước đây có thể kết luận rằng động lực làm việc ảnh hưởng tích cực đến hiệu quả công việc. Nhưng khi áp dụng vào một doanh nghiệp hoặc nhóm đối tượng khác, kết quả có thể không còn giống nhau do sự khác biệt về môi trường, văn hóa tổ chức hoặc đặc điểm mẫu khảo sát. Vấn đề không phải là cố làm cho kết quả giống giả thuyết, mà là phải hiểu tại sao kết quả lại như vậy.
Nguyên nhân thứ nhất: Dữ liệu khảo sát chưa phản ánh đúng vấn đề nghiên cứu
Dữ liệu là nền tảng quyết định kết quả mô hình. Một mô hình lý thuyết tốt nhưng dữ liệu thu thập không phù hợp thì kết quả vẫn có thể không đạt.
Một số tình trạng thường gặp là người trả lời khảo sát không đúng đối tượng nghiên cứu, trả lời theo cảm tính hoặc chọn cùng một mức điểm cho hầu hết câu hỏi. Khi đó, dữ liệu sẽ thiếu sự khác biệt giữa các nhóm quan sát.
Ví dụ, nếu 300 người khảo sát đều đánh giá tất cả tiêu chí ở mức 4 hoặc 5 thì các biến nghiên cứu sẽ rất khó thể hiện sự khác biệt. Khi đưa vào mô hình hồi quy hoặc SEM, các tác động có thể yếu đi và dẫn đến kết quả không giống giả thuyết.
Nguyên nhân thứ hai: Thang đo chưa tốt
Trước khi chạy mô hình, cần đảm bảo thang đo đo lường đúng khái niệm nghiên cứu.
Trong SPSS, các bước như Cronbach Alpha và EFA đóng vai trò rất quan trọng. Nếu một nhóm biến quan sát không thực sự đo cùng một khái niệm, kết quả phân tích phía sau sẽ bị ảnh hưởng.
Ví dụ, một nhân tố “Sự hài lòng” có 5 câu hỏi nhưng trong đó có một câu hỏi người trả lời hiểu theo hướng khác. Biến này có thể làm giảm độ tin cậy của thang đo và khiến mối quan hệ giữa các nhân tố trở nên yếu hơn.
Trong SmartPLS, các vấn đề tương tự thể hiện qua Outer Loading thấp, AVE thấp hoặc HTMT không đạt. Khi thang đo chưa ổn, việc chạy model và kỳ vọng tất cả giả thuyết đều đúng thường rất khó.
Nguyên nhân thứ ba: Mô hình nghiên cứu quá phức tạp
Nhiều nghiên cứu gặp vấn đề vì đưa quá nhiều biến vào mô hình.
Ví dụ, một mô hình có nhiều biến như trên. Khi các biến có nội dung gần giống nhau, chúng sẽ cạnh tranh ảnh hưởng với nhau. Kết quả là từng biến riêng lẻ có thể không còn ý nghĩa thống kê dù nhìn riêng từng biến vẫn có vẻ hợp lý.
Trong hồi quy SPSS, hiện tượng này thường liên quan đến đa cộng tuyến. Khi VIF cao, hệ số hồi quy có thể thay đổi mạnh và Sig của biến tăng lên.
Trong SEM, việc đưa quá nhiều mối quan hệ không cần thiết cũng có thể làm mô hình khó đạt độ phù hợp.
Nguyên nhân thứ tư: Có hiện tượng đa cộng tuyến
Đây là một nguyên nhân rất thường gặp khiến model chạy không giống giả thuyết.
Ví dụ nghiên cứu có các biến:
- Chất lượng sản phẩm
- Giá trị cảm nhận
- Sự hài lòng
Ba yếu tố này có thể liên quan rất chặt với nhau. Khi đưa chung vào mô hình, chúng có thể làm ảnh hưởng lẫn nhau.
Một biến ban đầu có tác động mạnh khi đứng riêng có thể trở nên không còn ý nghĩa khi xuất hiện cùng các biến khác.
Trong SPSS có thể kiểm tra thông qua:
- VIF
- Tolerance
Nếu VIF quá cao, cần xem xét lại cấu trúc mô hình hoặc cách đo lường biến.
Nếu hệ số bị ngược chiều so với giả thuyết thì sao?
Đây là trường hợp dở khóc dở cười, giả thiết sig vẫn đạt.
Ví dụ giả thuyết:
“Hài lòng khách hàng tác động tích cực đến ý định mua lại”
Nhưng kết quả lại:
Beta = -0.25
Sig < 0.05
Điều này có nghĩa là dữ liệu cho thấy tác động ngược chiều có ý nghĩa thống kê. Không nên lập tức kết luận dữ liệu sai. Có thể tồn tại nhiều lý do:
- Thứ nhất, biến nghiên cứu có thể chưa được đo đúng.
- Thứ hai, bối cảnh nghiên cứu có thể khác với các nghiên cứu trước.
- Thứ ba, có thể tồn tại một biến trung gian hoặc biến điều tiết chưa đưa vào mô hình.
Trong luận văn, trường hợp này cần được giải thích trong phần bàn luận thay vì cố xóa bỏ kết quả.
Có nên chỉnh dữ liệu để model đúng giả thuyết không?
Đây là câu hỏi rất thực tế, vì khi mô hình xấu sẽ khó để lý giải.
Thực tế, xử lý dữ liệu là một phần bình thường của nghiên cứu. Việc làm sạch dữ liệu, kiểm tra dữ liệu lỗi, xử lý các câu trả lời bất thường hoặc loại bỏ mẫu không phù hợp là cần thiết.
Cách đúng là tìm nguyên nhân tại sao model chưa phù hợp và cải thiện mô hình dựa trên cơ sở thống kê. Phần này nếu bạn cần tư vấn hỗ trợ xử lý để số liệu ra đẹp thì cứ zalo 0903396688 cho Ths Khánh nhé.
Khi chạy model không đúng giả thuyết nên kiểm tra gì?
Trước khi kết luận nghiên cứu thất bại, nên kiểm tra lại toàn bộ quy trình:
- Dữ liệu có sạch không?
- Mẫu khảo sát có đúng đối tượng không?
- Thang đo có đạt yêu cầu không?
- Có biến nào bị đa cộng tuyến không?
- Kích thước mẫu có đủ không?
- Mô hình lý thuyết có phù hợp với bối cảnh nghiên cứu không?
Có thể chỉ cần điều chỉnh một vài vấn đề trong dữ liệu hoặc mô hình thì kết quả sẽ thay đổi đáng kể.
Kết luận
Chạy model không đúng giả thuyết là tình trạng xảy ra thường xuyên trong các nghiên cứu định lượng. Một kết quả không giống kỳ vọng không đồng nghĩa với việc nghiên cứu thất bại. Nếu gặp trường hợp này hãy liên hệ page để được tư vấn + xử lý dứt điểm nhé
Liên hệ nhóm thạc sĩ Hỗ trợ SPSS.
– SMS, Zalo, Viber:

- Giá trị Communalities trong phân tích nhân tố EFA
- Phân tích số liệu khi làm luận văn là làm những gì?
- Tải SmartPLS 4 miễn phí vĩnh viễn không giới hạn sử dụng máy ảo VMware
- Dữ liệu thế này có làm luận văn được không?
- Mô hình IPA mức độ quan trọng – mức độ thực hiện (IPA – Importance-Performance Analysis)