Làm sạch và xử lý số liệu là một bước quan trọng trước khi thực hiện bất kỳ phân tích thống kê nào trong SPSS. Nếu dữ liệu không chính xác hoặc bị lỗi, kết quả phân tích sẽ không đáng tin cậy. Vì vậy, hiểu cách làm sạch và xử lý số liệu đúng cách sẽ giúp bạn có được kết quả phân tích chính xác và hiệu quả. Bài viết này nhóm MBA Bách Khoa sẽ hướng dẫn bạn các phương pháp làm sạch và xử lý số liệu trong SPSS, từ việc loại bỏ các giá trị thiếu cho đến chuẩn hóa dữ liệu.
Kiểm tra và xử lý dữ liệu thiếu – missing data
Dữ liệu thiếu là vấn đề phổ biến trong nghiên cứu và có thể ảnh hưởng nghiêm trọng đến kết quả phân tích. SPSS cung cấp nhiều phương pháp để xử lý dữ liệu thiếu, từ việc loại bỏ trường hợp thiếu dữ liệu đến thay thế các giá trị thiếu bằng các ước lượng hợp lý.
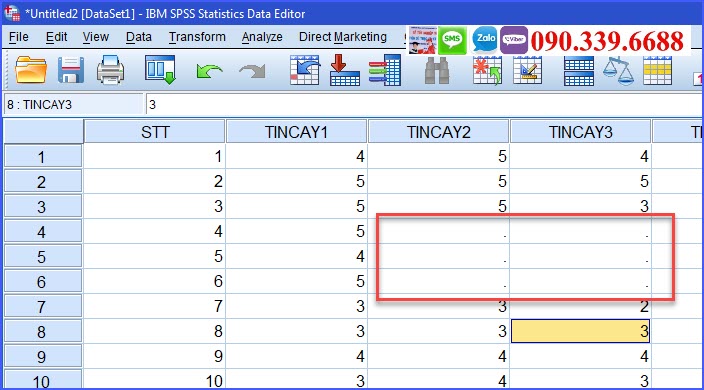
Hình dưới đây, một số quan sát của phiếu trả lời thứ tự 4 5 và 6 bị thiếu( được tô đỏ), dây chính là các giá trị missing value.
Cách xử lý dữ liệu thiếu
Loại bỏ trường hợp thiếu dữ liệu: Trong trường hợp dữ liệu thiếu ở một số mẫu, bạn có thể loại bỏ chúng để không làm sai lệch kết quả phân tích. Ví dụ bỏ quan sát 4 5 6 ở trên.
Thay thế dữ liệu thiếu: Bạn có thể thay thế các giá trị thiếu bằng giá trị trung bình, trung vị, như bài trên, nếu số mẫu khá ít, bạn có thể thay thế các giá trị trống bằng giá trị trung bình của các câu hỏi trong cùng NHÂN TỐ( chứ không phải là tất cả các câu hỏi trong bảng khảo sát nhé)
Hướng dẫn trong SPSS:
Vào Analyze > Descriptive Statistics > Explore.
Chọn các biến cần kiểm tra dữ liệu thiếu, ở đây chọn biến TINCAY3
SPSS sẽ hiển thị thông tin về dữ liệu bị thiếu để bạn có thể quyết định cách xử lý.
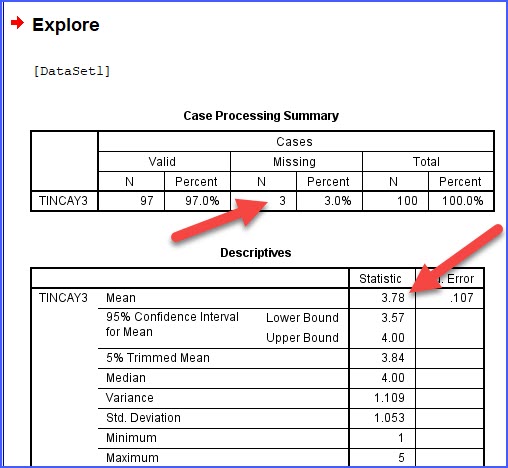
Có hai lưu ý, mục Missing có N=3, nghĩa là 3 dòng bị thiếu. Còn mục mean là 3.78, do đó nếu bạn muốn giữ 3 dòng này lại thì có thể gán giá trị 4(là giá trị làm tròn của 3.78) vào 3 ô trống đó, hoặc gán giá trị trung bình trong cùng 1 dòng của các biến TINCAY khác mà không bị thiếu.
Xử lý giá trị ngoại lai outliers
Giá trị ngoại lai (outliers) là các điểm dữ liệu có giá trị quá cao hoặc quá thấp so với phần còn lại của dữ liệu, có thể làm sai lệch kết quả phân tích thống kê.
Cách phát hiện và xử lý outliers
- Phát hiện outliers: Bạn có thể sử dụng biểu đồ Boxplot để xác định các giá trị ngoại lai.
- Xử lý outliers: Các cách xử lý bao gồm loại bỏ, thay thế hoặc điều chỉnh các giá trị ngoại lai.
- Hướng dẫn trong SPSS: xem chi tiết ở bài sau https://phantichspss.com/cach-doc-bieu-do-hop-boxplot.html
Đại khái là vào chọn menu Analyze –> Descriptive Statistics –> Explore
Chọn biến cần phân tích vào cửa sổ “Dependent List“.
Bấm “Statistics“, và chọn “Outliers“
Quan sát các điểm dữ liệu nằm ngoài hộp (outliers) và quyết định xử lý phù hợp.
Chuẩn hóa dữ liệu
Khi dữ liệu có sự chênh lệch lớn giữa các biến, chuẩn hóa dữ liệu là bước quan trọng giúp các giá trị trở nên đồng nhất, giúp việc phân tích thống kê trở nên chính xác hơn.
Kiểm tra tính đồng nhất của dữ liệu
Tính đồng nhất của dữ liệu rất quan trọng để đảm bảo rằng tất cả các giá trị trong một biến đều nhất quán. Ví dụ, một biến giới tính có thể có các giá trị “Nam”, “Nữ”, nhưng có thể có một số trường hợp ghi sai như ” Nam ” (với dấu cách thừa).

Như hình trên, dòng dầu tiên là ” Nam” có tần số 1 người. Làm ảnh hưởng xấu đến kết quả thống kê
Cách Kiểm Tra và Xử Lý Tính Đồng Nhất
Kiểm tra lỗi nhập liệu: Sử dụng các công cụ kiểm tra lỗi của SPSS để phát hiện những giá trị không hợp lệ. Như thống kê tần số để tìm ra biến bị lỗi
Sửa lỗi dữ liệu: Sử dụng tính năng tìm và thay thế trong SPSS để sửa các lỗi phổ biến.
Hướng dẫn trong SPSS:
Vào Data > Select Cases để chọn các trường hợp không hợp lệ.
Sử dụng Replace trong Edit để sửa các giá trị lỗi.
Hoặc copy toàn bộ cột có giá trị lỗi ra excel, sau đó replace bên excel, sau đó dán ngược qua
Chuyển đổi dữ liệu (data transformation)
Đôi khi, bạn cần chuyển đổi dữ liệu từ dạng này sang dạng khác để phục vụ cho phân tích. Ví dụ, bạn có thể muốn chuyển đổi một biến từ dạng số liệu liên tục sang dạng phân loại.
Cách chuyển đổi dữ liệu
Chuyển đổi số liệu liên tục thành phân loại: Bạn có thể phân chia một biến liên tục thành các nhóm phân loại như “Thấp”, “Trung bình”, “Cao”.
Hướng dẫn trong SPSS: vào Transform > Recode into different variables.
Chọn biến cần chuyển đổi và xác định các mức phân loại. Chi tiết bạn vui lòng xem bài này https://phantichspss.com/cach-ma-hoa-bien-bang-lenh-recode.html
Tóm lại
Làm sạch và xử lý số liệu trước khi phân tích là một bước không thể thiếu trong nghiên cứu. Việc loại bỏ các giá trị thiếu, xử lý outliers, chuẩn hóa và kiểm tra tính đồng nhất của dữ liệu sẽ giúp bạn có được kết quả phân tích chính xác và đáng tin cậy. SPSS cung cấp nhiều công cụ mạnh mẽ để hỗ trợ bạn trong quá trình này. Nếu bạn gặp khó khăn trong việc xử lý số liệu, đừng ngần ngại tìm đến dịch vụ xử lý số liệu chuyên nghiệp của nhóm MBA Bách Khoa để có kết quả tối ưu.
Mọi sự hỗ trợ hãy liên hệ Thạc Sĩ Khánh và nhóm MBA tại zalo 0903396688
Liên hệ nhóm thạc sĩ Hỗ trợ SPSS.
– SMS, Zalo, Viber:

- Vì sao Cronbachs Alpha cao vẫn sai? Hiểu đúng để không rớt luận văn
- Cách chạy phân tích tương quan với SPSS
- Kiểm định Chi bình phương Chi Square test: cách thực hiện, cách đọc kết quả, cách thao tác tính toán bằng tay thay vì dùng SPSS
- Hướng dẫn kiểm định Bootstrap trong SmartPLS: Cách thực hiện và ý nghĩa
- Tổng quan phân tích nhân tố khám phá EFA